
图灵奖得主Sutton新作:AI的下一步,是走向「生成认知」
图灵奖得主Sutton新作:AI的下一步,是走向「生成认知」从 LLM 的超长文本处理、视频生成模型的以假乱真、Agent 自主规划与执行的日趋成熟,到 VLA、世界模型等开始进入物理世界,AI 正在不断拓宽其能力边界。
来自主题: AI技术研报
6857 点击 2026-06-02 15:05
 搜索
搜索
从 LLM 的超长文本处理、视频生成模型的以假乱真、Agent 自主规划与执行的日趋成熟,到 VLA、世界模型等开始进入物理世界,AI 正在不断拓宽其能力边界。
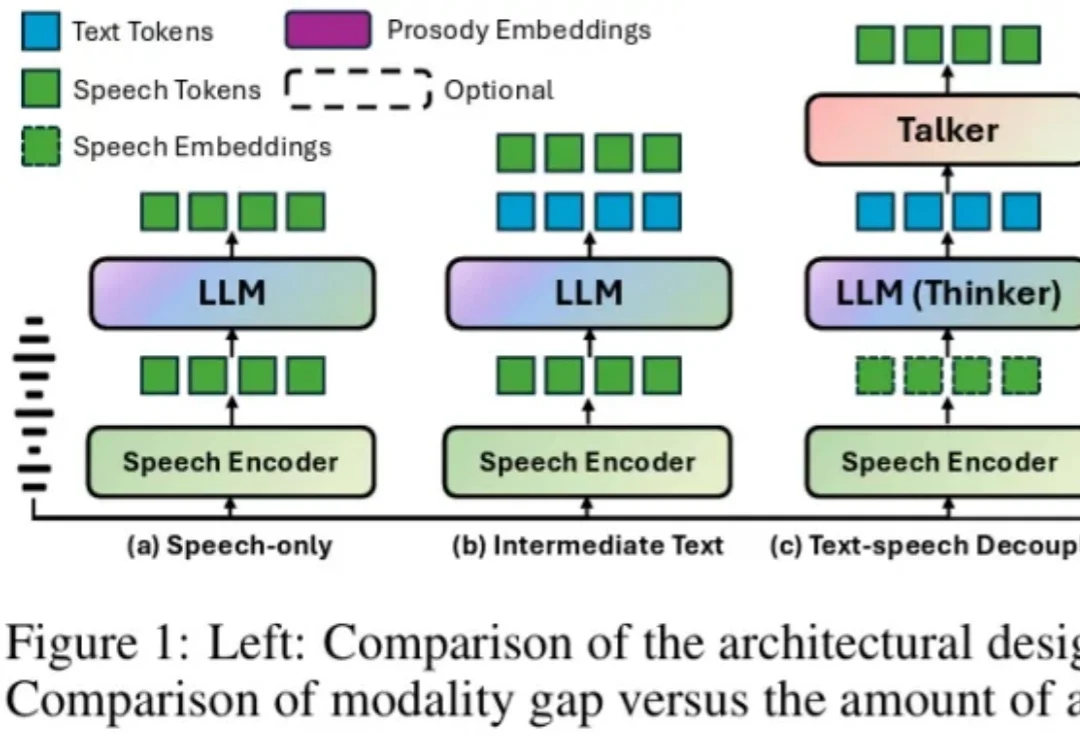
相信大家都有过这样的体验:同一个系列的模型,使用文本交互的时候,模型就像开启了 “最强大脑”,数学代码等各种复杂推理任务样样精通,可是一旦将其改造成语音对话模型之后,性能就猛烈下降,严重 “降智”,经常会犯很多基本的逻辑错误。

今年以来,在线策略蒸馏 OPD(On-Policy Distillation)已经逐渐成为大厂 LLM 后训练中的重要组件,例如 DeepSeek-V4,GLM5 就使用了多教师 OPD 来整合不同领域专家模型的能力,相比混合奖励强化学习收敛更快、效果更好。
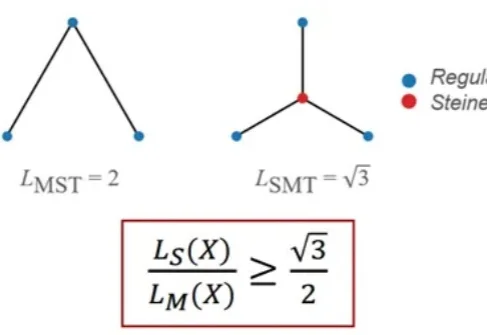
近期,LLM 已经在 IMO 上取得了很好的成绩,在一些研究级数学上(如短程证明、组合构造)也有所进展。但如果真正让 LLM 去处理提出数十年的数学猜想,结果会是如何?
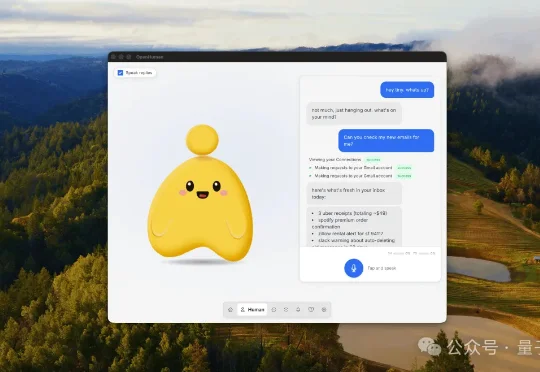
虾在前,马当道,居然还有新物种能在Agent赛道突出重围。OpenHuman连续霸榜GitHub Trending第一,狂揽9k+ Star,一天就涨千星。和虾马不一样,Human不用你花心思养,还能反过来主动了解你。

为了解决这一问题,来自中山大学和美团的研究团队提出了 X2SAM,一个统一的图像与视频分割多模态大模型框架。它希望让模型不仅能「看懂」图像和视频,还能进一步「指出」目标在每个像素上的准确位置。
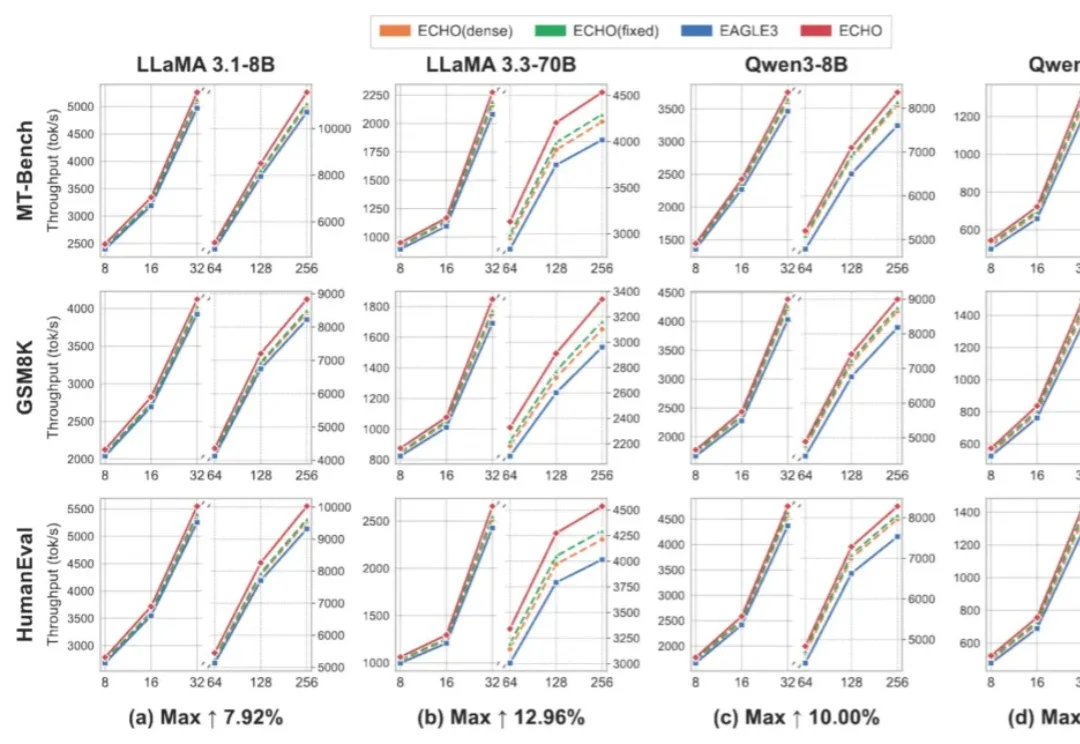
随着大模型参数规模持续扩大,推理成本已经成为生产级 LLM 服务的核心瓶颈。投机解码(Speculative Decoding, SD)通过「小模型 draft + 大模型 verify」的方式,将多个候选 token 放到一次目标模型前向中并行验证,从而缓解自回归解码的串行瓶颈。

“LLM 就是一条死路。”
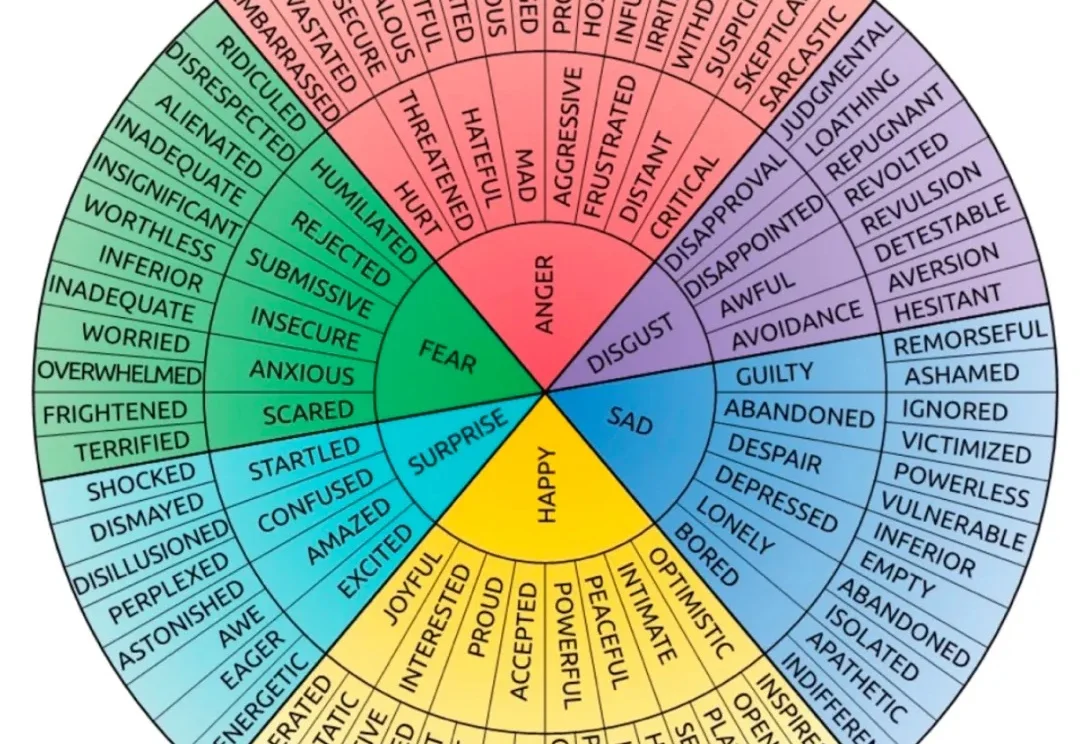
随着语音、视频、多模态能力不断融入大语言模型(LLM),人与 AI 的交互正在越来越接近自然对话。今天的 LLM 不再只是回答问题的工具,也越来越多地出现在教育、客服、陪伴、心理健康等高度依赖情绪理解的场景中。
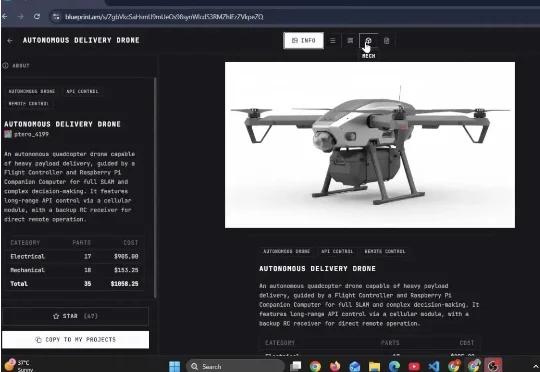
大家好,最近有人刚刚为电子产品开发了一个 Claude Code 工具。 它叫做 Blueprint。输入你想要构建的内容,它就会为你的 Arduino 或树莓派项目生成接线图、物料清单和分步组装指南。能不能自己搭建一个呢?